Deepfakes是结合混合源材料以产生合成结果的图像和视频。它们的使用范围从微不足道到恶意,因此检测它们的方法受到追捧,最新技术通常基于使用原始图像和合成图像对训练的网络。一种新方法通过使用以独特方式创建的新型合成图像来训练算法,从而打破了这一惯例。这些新颖的训练数据被称为自混合图像,可以明显改进旨在发现深度伪造图像和视频的算法。
眼见为实,所以他们说。然而,自从有记录的视觉媒体出现以来,总是有人试图欺骗。事情的范围从琐碎的事情,例如不明飞行物的假电影,到更严重的事情,例如从官方照片中删除政治人物。Deepfakes只是一系列操纵技术中的最新一种,它们作为令人信服的现实通过的能力远远超过了发现它们的工具的进步。
东京大学计算机视觉和媒体实验室的副教授ToshihikoYamasaki和研究生KaedeShiohara探索了与人工智能相关的漏洞等。deepfakes问题引起了他们的兴趣,他们决定研究改进合成内容检测的方法。
“有许多不同的方法可以检测深度伪造,还有各种可用于开发新的训练数据集,”Yamasaki说。“问题是现有的检测方法往往在训练集的范围内表现良好,但在多个数据集上表现不佳,或者更重要的是,当与最先进的现实世界示例进行对比时。我们感受到了这种方式改进成功检测可能是重新考虑使用训练数据的方式。这导致我们开发了我们所谓的自混合图像(也称为SBI)。
指出不同。使用不同的处理方法(DF、F2F、FS和NT)制作了一些deepfake照片的示例。然后使用已建立的样本deepfake(FF++)数据集训练deepfake检测器,同时使用研究人员的自混合图像(SBI)训练重复检测器。两个检测器都获得了上面的deepfake照片。假彩色图像的列显示了使用现有数据集进行训练和使用SBI进行训练之间的差异。图片来源:©2022Yamasaki和Shiohara
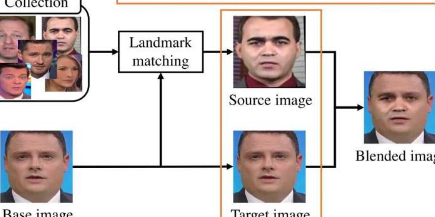
用于深度伪造检测的典型训练数据由成对的图像组成,包括未经处理的源图像和对应的伪造图像——例如,某人的脸部或整个身体已被其他人的脸部或全身替换。使用这种数据进行的训练限制了对某些类型的视觉损坏或伪影的检测,这些视觉损坏或伪影是由操纵导致的,但错过了其他。因此,他们尝试了包含合成图像的训练集。通过这种方式,他们可以控制训练图像包含的伪影类型,进而可以更好地训练检测算法来发现这些伪影。
“本质上,我们从已建立的数据集中获取了人的干净源图像,并引入了不同的细微伪影,例如,调整图像大小或重塑图像,”Yamasaki说。“然后我们将该图像与原始未更改的源混合。混合这些图像的过程还取决于源图像的特征——基本上会制作一个蒙版,以便只有经过处理的图像的某些部分才能进入混合输出.许多SBI被编译到我们修改后的数据集中,然后我们用它来训练检测器。”
该团队发现,修改后的数据集将准确检测率提高了约5-12%,具体取决于与它们进行比较的原始数据集。这些可能听起来不像是巨大的改进,但它可能会在有恶意的人成功或未能以某种方式影响他们的目标受众之间产生差异。
“当然,我们希望改进这个想法。目前,它在静止图像上效果最好,但视频可能有我们无法检测到的时间伪影。此外,deepfakes通常只是部分合成。我们也可能会探索检测完全合成的方法图像,”山崎说。“然而,我设想在不久的将来,这种研究可能会在社交媒体平台和其他服务提供商上发挥作用,以便他们能够更好地标记可能被操纵的图像并发出某种警告。”
标签:
版权声明:本文由用户上传,如有侵权请联系删除!